
.png?width=2000&height=2000&name=Online%20test-amico%20(2).png)
The security of high-stakes assessments that have been re-used or implemented online has been a growing concern. While often discussed as a cheating problem on exams (e.g., Chen et al., 2018; Fowler et al., 2022), even longer programming projects which can make up a meaningful portion of a student’s grade can be at risk for plagiarism (e.g., Irvine et al., 2017).
Assignments that are asynchronous, where students complete them at different times within a given window, can lead to collaborative cheating - where the student who completes the assignment earlier passes information to a student who completes it later (Chen, West & Zilles, 2018).

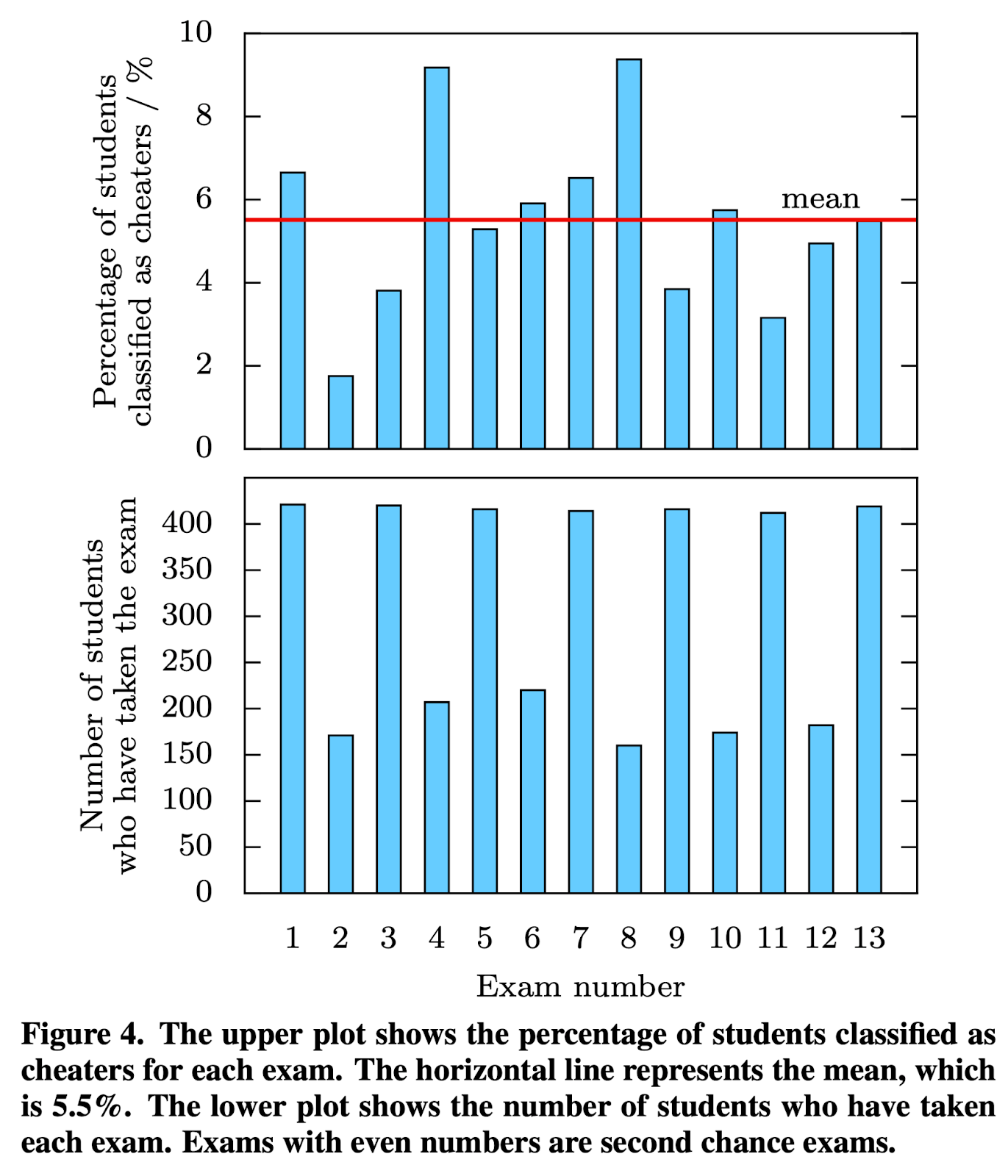
Chen and colleagues (2018) found that, on average, 5.5% of students cheat on asynchronous exams, with no more than 10% on any given exam (as shown in Chen, West & Zilles, 2018 - Figure 4, reproduced below).
Old Approach: Detecting Plagiarism
Most institutions handle academic dishonesty through detection after the fact. Considering a Computer Science course, the two high-stakes types of assignments are generally (1) exams and (2) programming projects.
Detecting Plagiarism in Computing Exams
One of the main ways to detect cheating on exams is proctoring. Chen et al. 2020 compared exams taken at an on-campus, proctored Computer-Based Testing Facility to unproctored exams within the same introductory programming course.
“We found that students scored 3.32 percentage points higher on questions on unproctored exams than on proctored exams (p < 0.001). More interestingly, however, we discovered that this score advantage on unproctored exams grew steadily as the semester progressed, from around 0 percentage points at the start of the semester to around 7 percentage points by the end.” (Chen et al., 2020)
Chen and colleagues (2020) also noted that due to the lower randomization and higher-point values, the positive advantage of unproctored exams was statistically significant for the programming question type (as shown in Chen et al., 2020 - Figure 8, reproduced below).

Plagiarism Detection in Online Exams
With the recent shift to online education, where cheating is even more rampant, we have seen a growing adoption of remote proctoring tools such as Respondus and Proctorio
However, this has raised questions about the ethics of proctoring – mainly automated, remote proctoring:
“Faculty demand for surveillance technology reflects an ethical framework rooted in justice ethics rather than care ethics. The goal of surveillance is to enforce rules….and to catch and punish those who violate those rules. ….From the standpoint of an ethics of care, the questions that need to be raised are quite different…. Why our students are cheating…[and] whether we should require our students to use technology that frames students as suspects from the beginning” (Tomsons, 2022).
In fact, certain states, such as Illinois, have laws that protect students from the level of invasive data collection that these systems require, and students at Northwestern University and DePaul Univerity have filed lawsuits against their institutions.
Academic Integrity Issues in Programming Projects
Malan, Yu, and Lloyd (2020) describe that it still feels important to have programming assignments make up a large portion of the course grade because “students spend most of their time on (and learn most from, we hope) the course’s problem sets” instead of relying on proctored exams. However, these programming experiences also have plagiarism concerns. Malan’s team, through a mixture of software plagiarism tools (e.g. MOSS, ETector, and compare50) and manual review, “referred nearly 4% of its student body to the university’s honor council” (as shown in Malan et. al., 2020 - Figure 3 reproduced below).
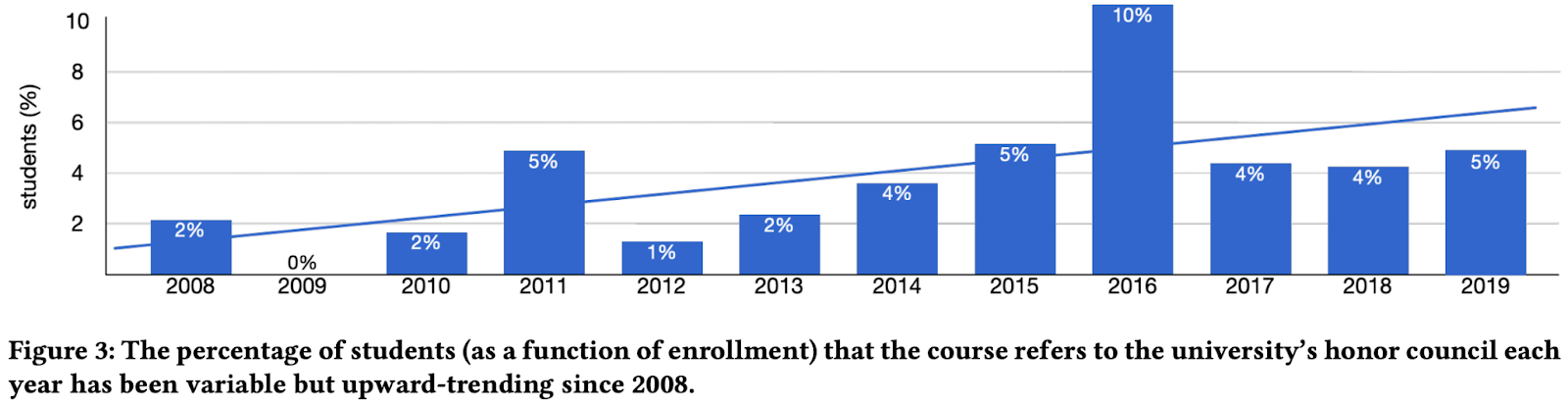
Unsurprisingly, even with software tools and hours of manual review, the process is far from perfect. “Remarkably, among the dozens of students who have come forward under [the regret] clause since 2014 to admit some act of dishonesty, few of those acts were even detected by software. Had those students not come forward on their own, most would not have appeared on our radar at all.”
Source code comparison software is problematic in that the software is only comparing within the provided set of code submissions, meaning previous semester submissions or even similar problems at other universities whose solutions are posted on the internet are not considered. One approach that faculty have noted is that if one student finds a solution online, then other students will also, which will flag a similarity between the two assignments.
New Approach: Plagiarism Prevention
One way to prevent this is to give each student different assessments. Two common approaches to accomplish this are (1) pulling a randomized assessment from a question bank and (2) generating individual questions (e.g. Chen et al., 2018; Fowler et al., 2022).
Approach #1: Random Assessment Item from Question Bank
Similar to having multiple versions of a test, a number of systems support pulling, at random, a question out of a pool of questions. Whether this pool is called a question bank or assessments library, instructors often have to pre-build these sets of questions before assigning a randomized assessment.
Codio provides a pre-built, fully auto-graded assessments library in addition to allowing instructors to build their own assessment libraries. Instructors can then pull random assessments from an assessment library.
Approach #2: Generating Assessment Items using Parameterized Question Templates
Parameterized assessments or questions have randomly generated variables within the question template. This allows a large number of unique questions to be generated from a single-question template.

Example of a parameterized physics problem on PriarieLearn
PrairieLearn, an open-source tool out of the University of Illinois, has been the name in parameterized questions over the past decade. They have also recently launched a paid service for professors who do not want to self-host the PrairieLearn system. However, even without setting up hosting, getting started can be cumbersome - with each question requiring multiple files of different types (i.e., info.json, question.html, and server.py).
To help address the need for more easy-to-use parameterization, Codio released support for parameterized assessments in November 2022.
Multi-Variant Multiple-Choice Auto-Graded Assessment Questions
A specific way to leverage parameterized assessment generation is by randomly selecting multiple-choice answers without altering the question. Denny and colleagues (2019) personalized multiple choice exams “by generating multiple-variant MCQs, in which the answer options for a question are drawn at random from a pool of options defined by the instructor.”
They propose not just generating incorrect answer choices – but correct answer choices as well: “For a given question stem, the instructor creates a pool of multiple true answers (all of which are correct solutions to the question) and a separate pool of multiple false answers (which are all incorrect).”
How do you have a multiple-choice question with multiple correct answers? Denny and co-authors (2019) provide the following example:
Consider the following code that processes an array of integers (note that the values in the array are not displayed below):
|
int values[5] = { ..... }; |
Which array initialization would lead to the output x = 0?
Any array where the sum of the first two values and the last two values are equal would result in a correct answer.
This approach to personalization also means that these question stems can be used not just for single-response multiple-choice questions (where a single answer choice is correct), but also for generating multiple-response multiple-choice questions (where more than one answer choice may be correct).
Combining the Two Approaches: Randomized & Parameterized Assessments for CS Education
These two approaches can also be strategically combined. Chen, West, and Zilles (2018) found that when using a question bank “of 4 [parameterized questions], we found the mean score advantage of collaborative cheating to be less than 2 percentage points (statistically indistinguishable from zero), down from an advantage of 13 percentage points for pool size 1 where every student had the same problem generator.” This means that instead of writing several versions of each question to be selected at random, an instructor can write a few parameterized versions per question.
Fairness Across Unique Exams
Generating fair but unique exams used to involve large question banks with data on each question’s difficulty. This can be done programmatically, with the data stored in metadata and the overall difficulty of each exam being balanced upon generation. However, creating systems to do this balancing can be cumbersome.
Ensuring fair exams are generated can also be done manually by pruning “outlier” questions from question banks. Fowler and co-authors (2022) noted that the first semester of using randomized assessments had the most variance but “in subsequent semesters, the instructor had data with which to trim pools down and better balance pool difficulty.…it is likely the reduction in unfairness is largely due to exam construction, because we know the instructor adjusted pools to remove outlier questions.”
While this is viable upon the re-use of questions where you have historical performance data, this does not address newly created questions. Chen’s team (2019) found “that the use of automatic item generation by college faculty is warranted, because most problems don’t exhibit significant difficulty variation, and the few that do can be detected through automatic means and addressed by the faculty member.” Out of 378 generated item templates, 5.3% or 20 of them had statistically significant differences in difficulty between generated variants.
One example of an unfair question was a physics problem, where a parameter was used to randomly assign the particle as traveling right or left along its path. When the question is generated as the particle is traveling left, more students get the question wrong – probably because they forget to flip the sign (+ to -) of the given velocity. Another example is a math question asking students to translate Cartesian coordinates (x,y) to polar coordinates (r, θ). When x < 0, students are more likely to get the question wrong because they need to use the four-quadrant arc-tangent function instead of the arc-tangent – but these two functions return the same value when x > 0 (Chen et. al., 2019).
When creating parameterized question templates and attempting to ensure similar difficulty, it is not as simple as using discrete or continuous values for randomization – but more about being careful to consider how certain subsets of generated values might make students more likely to be confronted with a predictable mistake.
Denny’s team (2019) found that “many students are concerned about the fairness of [a personalized] form of assessment. Moreover, despite our test questions undergoing several rounds of internal review, there is clear evidence that some question variants were significantly easier than others.”
Programming Projects: Applying these Approaches Beyond Exams
While many of the studies cited above are specific to exams, the same approaches can be taken for programming projects or labs. Irvine, Thompson, and Khosalim (2017) built Labtainers, which are Docker-based containers for hands-on cyber security labs. One of the features of their Labtainers project was for the exercises to be parameterizable - “Each student will have a laboratory exercise that cannot be accomplished by simply copying the results of another student”.
Nakata and Otsuka (2021) described randomizing cyber range scenarios with multiple milestones, where each milestone is considered the same state. They create multiple paths from one state or milestone to the next - forming a directed acyclic graph (DAG), such as:
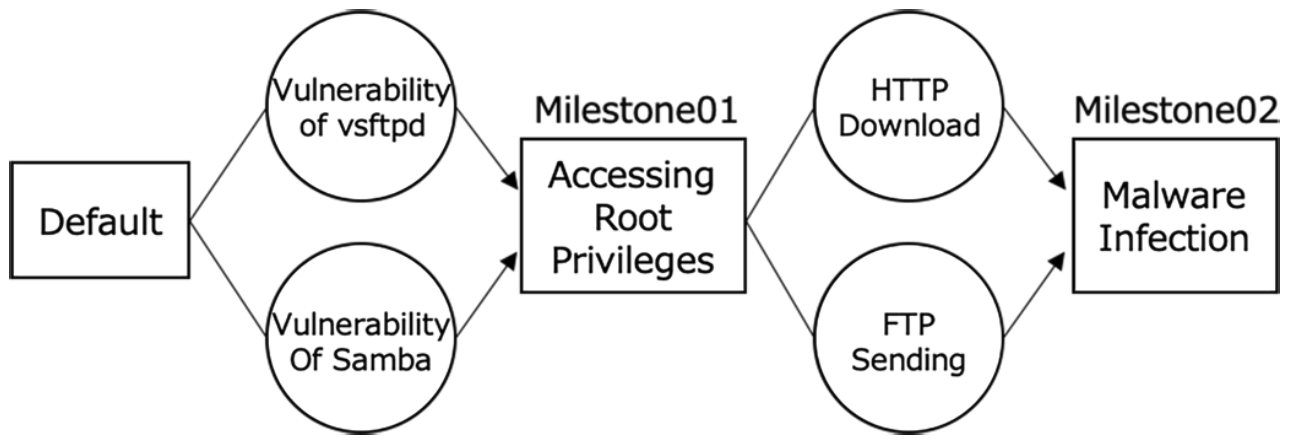
This approach is similar to randomized assessments in a question bank since each student is given one of the available scenarios created for each milestone. Interestingly, the multi-stage or milestone project approach has not only been shown to provide critical scaffolding to increase student performance on programming projects, and in this case also creates multiple opportunities for randomization.
Tools with “Evergreen” Functionalities
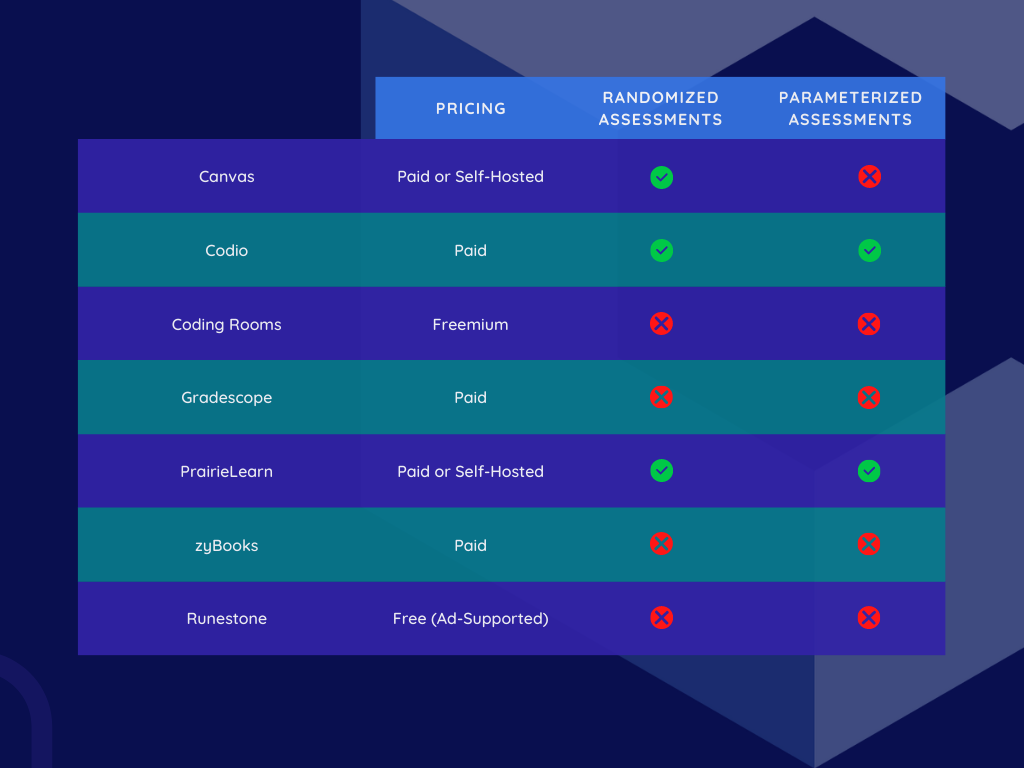
Many of the tools discussed above, such as Labtainers, were custom created by professors. However, there is slowly increasing support for “evergreen” content functionalities in commercial tools:
References
Chen, B., Azad, S., Fowler, M., West, M., & Zilles, C. (2020, August). Learning to cheat: quantifying changes in score advantage of unproctored assessments over time. In Proceedings of the Seventh ACM Conference on Learning@ Scale (pp. 197-206).
Chen, B., West, M., & Zilles, C. (2018, June). How much randomization is needed to deter collaborative cheating on asynchronous exams?. In Proceedings of the Fifth Annual ACM Conference on Learning at Scale (pp. 1-10).
Chen, B., Zilles, C., West, M., & Bretl, T. (2019, June). Effect of discrete and continuous parameter variation on difficulty in automatic item generation. In International Conference on Artificial Intelligence in Education (pp. 71-83). Springer, Cham.
Denny, P., Manoharan, S., Speidel, U., Russello, G., & Chang, A. (2019, February). On the fairness of multiple-variant multiple-choice examinations. In Proceedings of the 50th ACM Technical Symposium on Computer Science Education (pp. 462-468).
Fowler, M., Smith IV, D. H., Emeka, C., West, M., & Zilles, C. (2022, February). Are We Fair? Quantifying Score Impacts of Computer Science Exams with Randomized Question Pools. In Proceedings of the 53rd ACM Technical Symposium on Computer Science Education V. 1 (pp. 647-653).
Irvine, C. E., Thompson, M. F., & Khosalim, J. (2017). Labtainers: a framework for parameterized cybersecurity labs using containers.
Malan, D. J., Yu, B., & Lloyd, D. (2020, February). Teaching academic honesty in CS50. In Proceedings of the 51st ACM Technical Symposium on Computer Science Education (pp. 282-288).
Nakata, R., & Otsuka, A. (2021). CyExec*: A High-Performance Container-Based Cyber Range With Scenario Randomization. IEEE Access, 9, 109095-109114.
Tomsons, K. (2022). The Ethics of Care and Online Teaching: Personal Reflections on Pandemic Post-Secondary Instruction. Gender, Sex, and Tech!: An Intersectional Feminist Guide, 268.


