Essential Data Science in R
Constructing Knowledge Through Coding
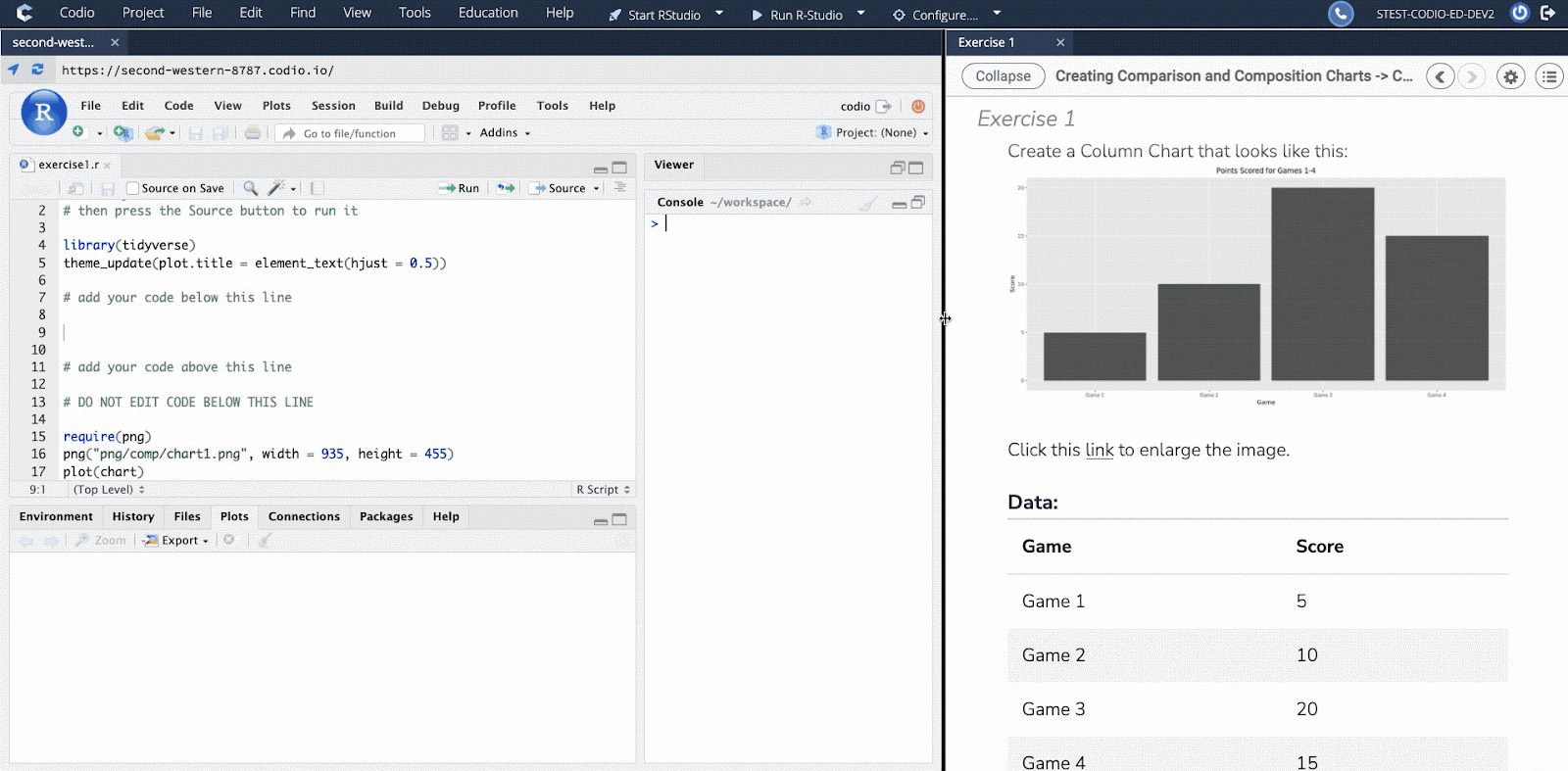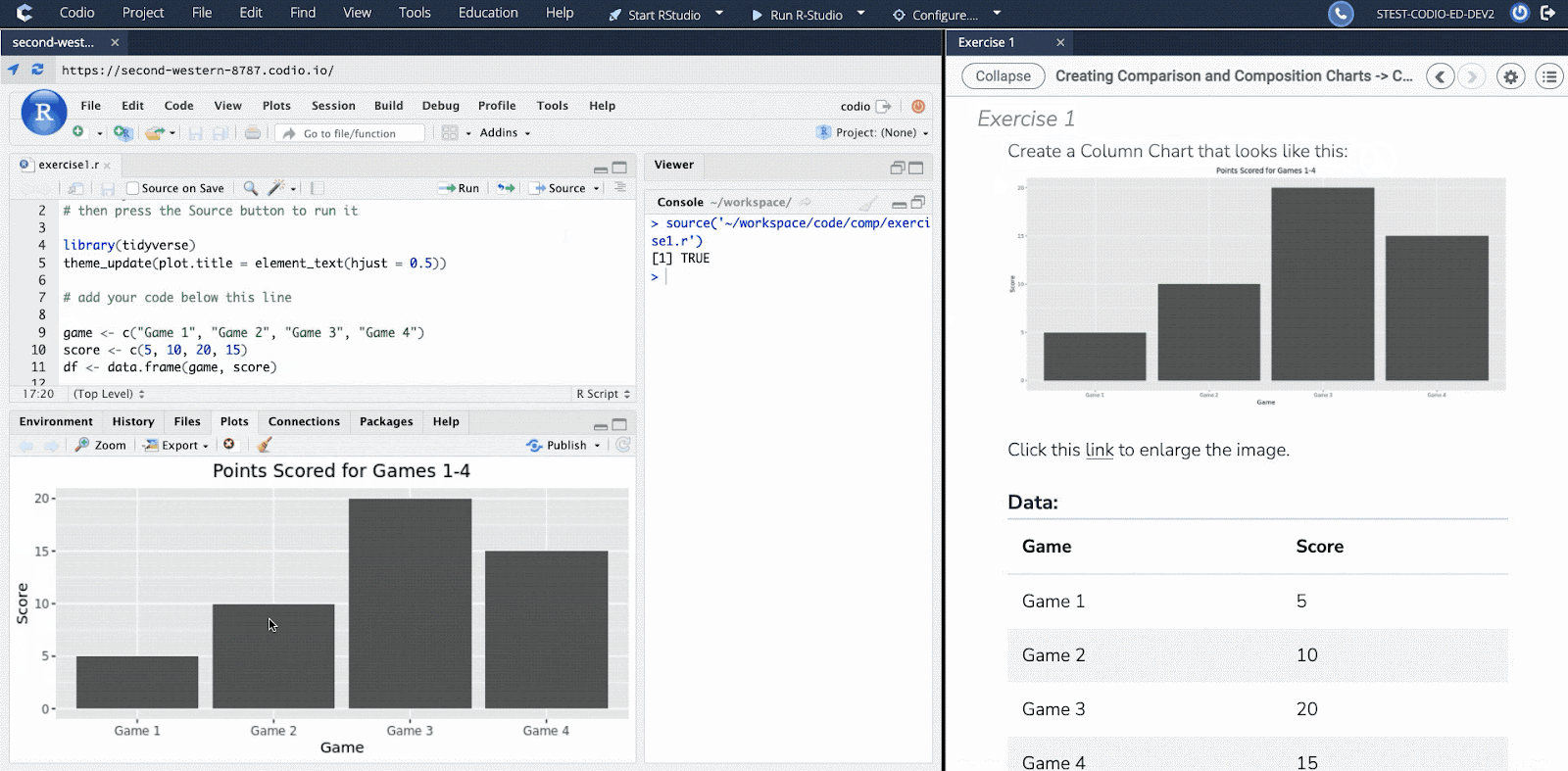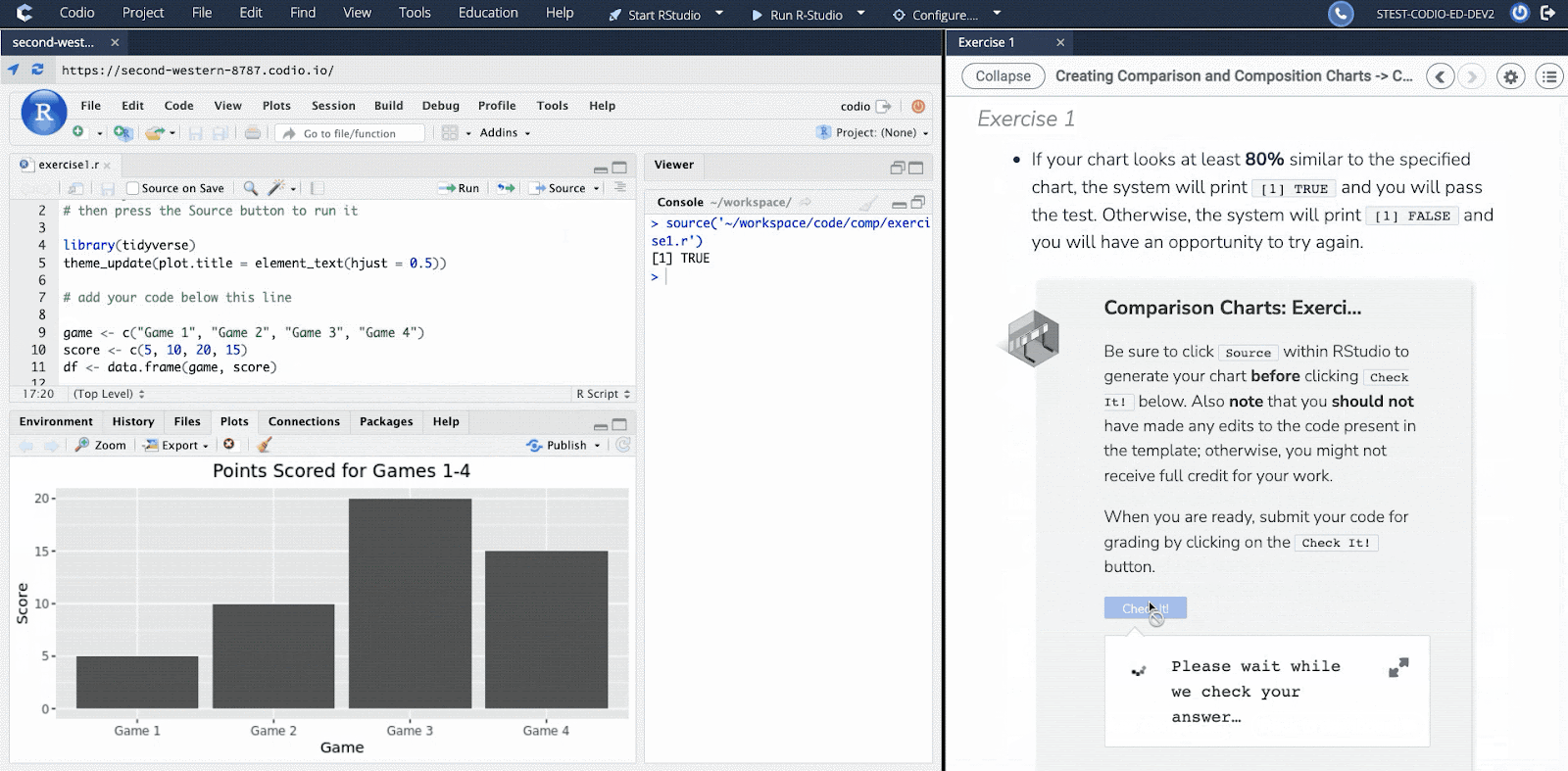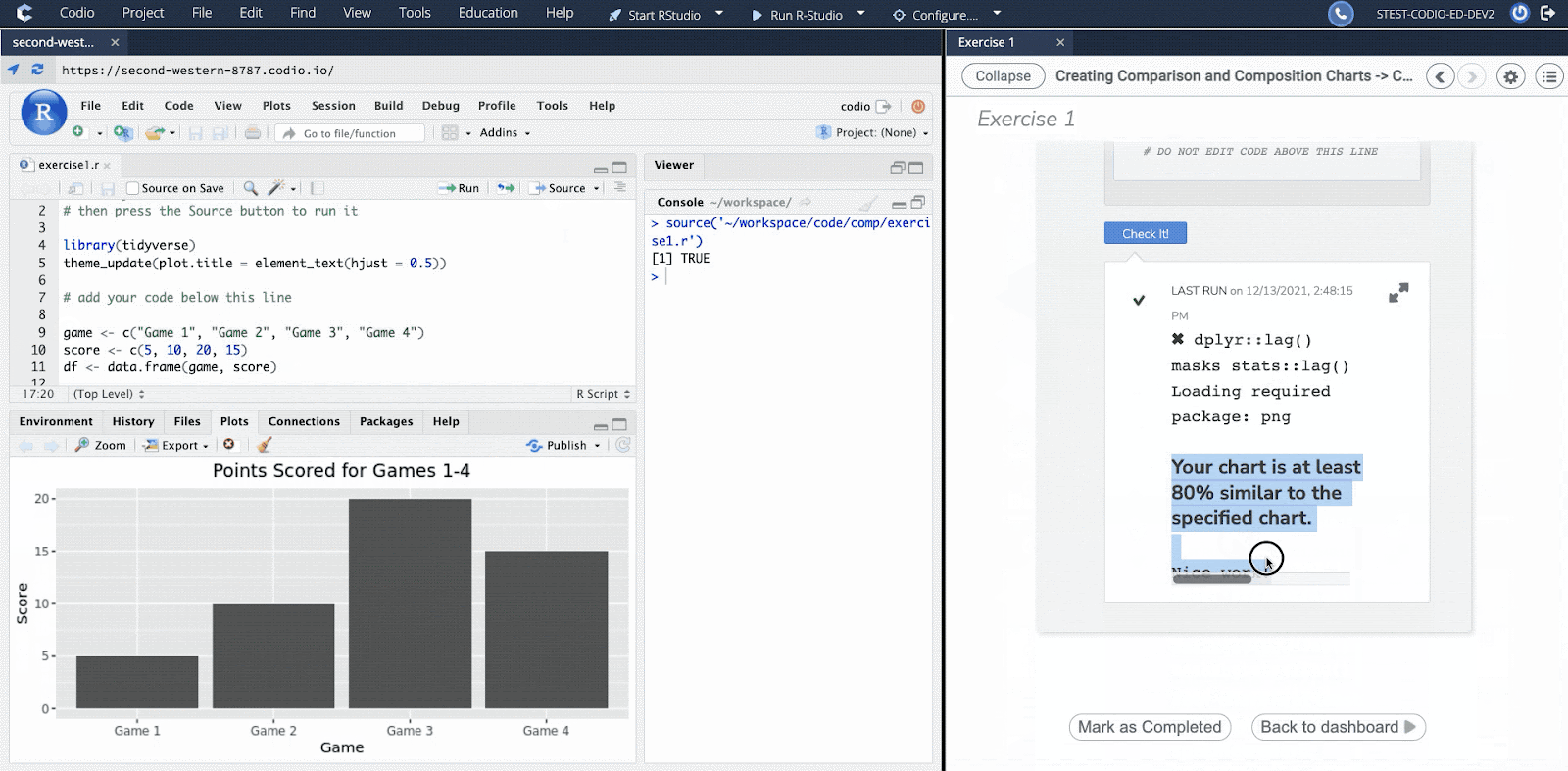
Essential Data Science in R emphasizes the importance of students applying and exploring the information presented. With Codio’s interactive interface, a code editor accompanies each page with new concepts. This way, students can actively see how the computer responds to code, rather than simply showing the end result. In addition, the course content provides code snippets that allow students to become familiar with the language, as well as suggested avenues for investigation.
Auto-Graded Assessments
We believe in the value of active feedback, which is why students receive immediate, rich feedback. In addition to feedback on the validity of a specific answer, students will also be provided with an explanation that includes the complete solution, as well as the steps that reached that destination. There are a wide variety of questions — all of which are auto-graded, giving students a sense of their understanding of the material right after they are introduced to it and as they attempt harder and harder problems.